
One of the perks of being an editor is learning new things. Getty Publications publishes over thirty books a year on art history, conservation, architecture, archaeology, and related fields, so every time we take on a book project, we learn about new discoveries, new models of interpretation, and even new words.
Still, as an editor I’m not often asked to learn new technologies. Sure, the usual operating system upgrades and updates to Microsoft Word can have me tearing out my hair, but the editor’s tools have remained remarkably unchanged since the dawn of word processing…that is, until e-books came along.
The Getty was relatively quick to embrace digital publishing, but for our early e-books, the editorial workflow remained much the same; only the end product was different. For our two new online collection catalogues, Ancient Terracottas from South Italy and Sicily and Roman Mosaics, however, we thought differently from the outset. We asked ourselves: How can we capture what’s best about a print book—its longevity, user-friendliness, and portability—alongside what’s best about an e-book, especially the ease of access and interactivity?
Our digital publications team came up with an innovative solution, which presents the content as a responsive website and paperback and offers free downloads of the book as EPUB, MOBI, and PDF, as well as exports of catalogue data and image sets. Under the hood for all these is a static-site generator that unites images and style sheets with text files that contain the entire content of the book.
With that innovative solution, however, came new processes for us editors—and, even a new vocabulary, one that includes words like markdown, git, pull request, repository, commit, clone, middleman, and a bunch of others that take on new meanings once you’ve dipped a toe into coding waters.
While I left the heavy technical lifting to our digital publications team, I nevertheless had to get cozy with GitHub, a web-based repository designed to support open-source software projects. For those who are interested how this art-book nerd became (sort of, a little bit) a coding nerd, well, read on.
Editing for Print
For a print book, I first work with the author using Track Changes in Microsoft Word. We spend a good amount of time developing the text before sending it off to copyediting and, finally, to design and production. The designer takes the Word documents and typesets the manuscript using Adobe InDesign (really, transforming the words and images of a book into a beautiful object in and of itself).
After all this I oversee the proofreading of the text, which is to say, poring over tabloid-sized sheets of paper (otherwise known as page proofs) and marking the pages by hand using proofreaders’ marks. The designer enters those corrections into the files, I recheck the proofs, and we repeat if necessary, until the pages are approved and the book can be sent off to the printer. There are a lot of other steps and numerous other people involved in the process, but for me, it’s all Word docs and page proofs (and, OK, the occasional PDF).

At work marking up page proofs for Ancient Terracottas. Photo: Eric Gardner
Editing for the Web
Ancient Terracottas began the same way as most of our other books, with a bunch of Word documents that had been passed around between the author in Italy, curators at the Getty Villa, the peer reviewer, the translator, the copyeditor, and me. But instead of going off to design for typesetting, those Word docs went off to our developer, Eric Gardner, to be transformed into the Markdown and YAML files that power the catalogue in all its forms.
Markdown is basically code lite. There are bits of code floating around—links, special styles of text like small caps, and images all require some knowledge of HTML—but for the most part, a Markdown file doesn’t look too different from a regular Word document. But unlike a Word document, it can be easily converted to numerous other formats, including HTML. And unlike an HTML file, you can actually read a Markdown file without any specialized knowledge. YAML files are similar—plain text and human-readable—except that in the context of our publishing system, they have the added power of transforming a collection catalogue into something that can function as a searchable, sortable database as well as a linear, readable book.
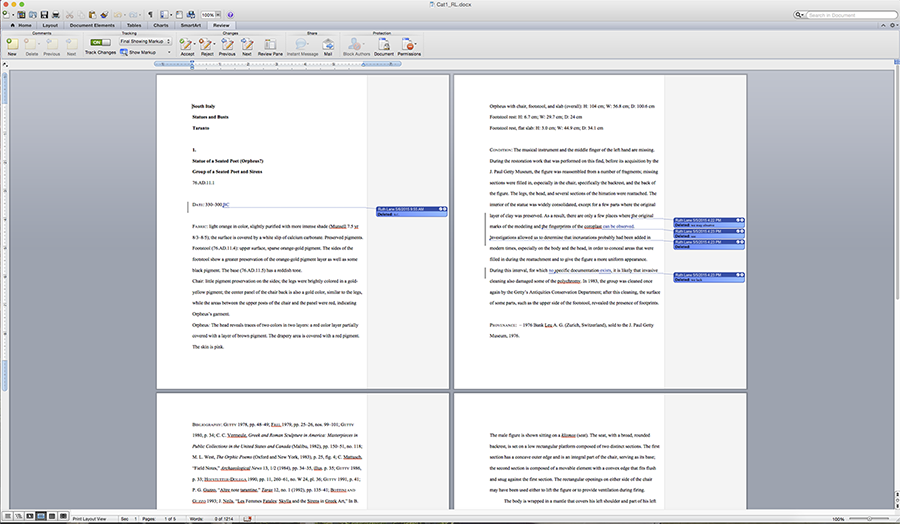
Microsoft Word file for a catalogue entry in Ancient Terracottas, with a few late-breaking edits, just before Eric transformed it into a YAML file.
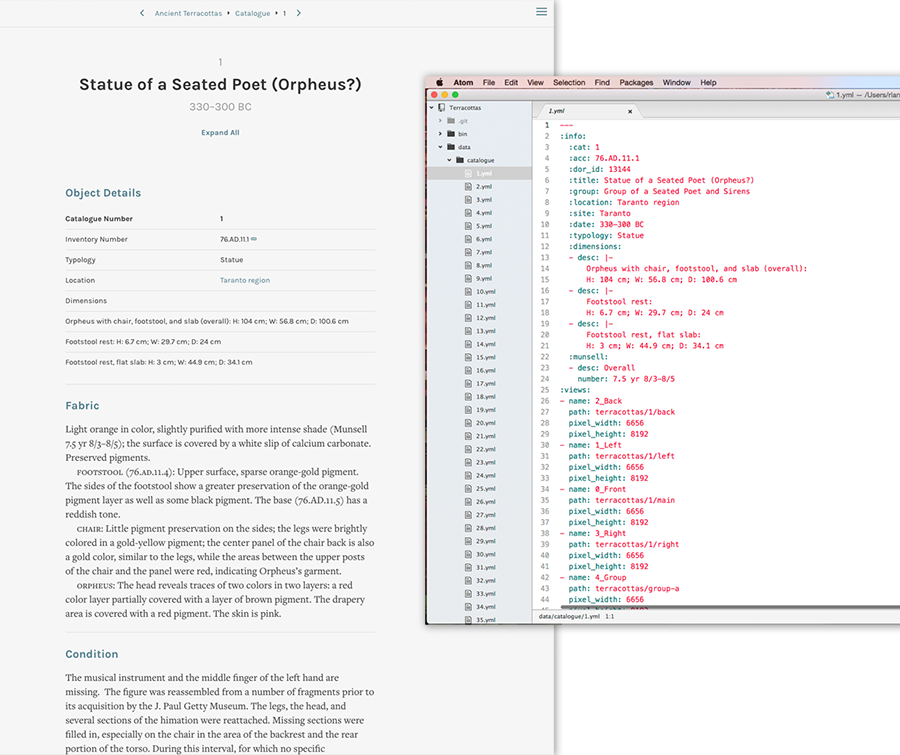
A catalogue entry (Cat. 1) from Ancient Terracottas as published on getty.edu (left) and as prepared in a YAML file (right). The data—like catalogue number, accession number, title, group, and location—are all separated out individually, which allows for sorting by date, typology, or location, and facilitates better searching.
After the Word documents were converted to Markdown and YAML files (and loads of other programming things happened), Eric produced a PDF and a beta version of the website for proofreading and user testing. The proofreading process for the PDFs wasn’t too different from that for a print book—we still looked at big tabloid-sized page proofs, alongside the website, and marked up corrections by hand—but instead of handing those proofs off to design to input the corrections, I downloaded GitHub and the text editor Atom and entered them myself, with some handholding from Eric and our digital publications manager, Greg Albers.
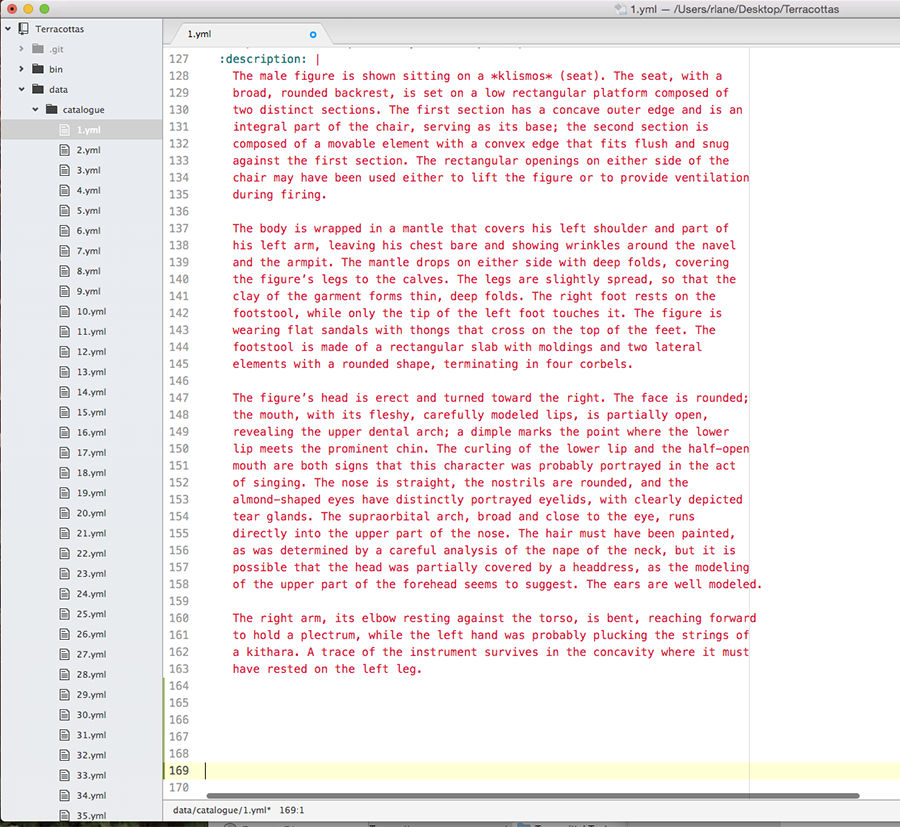
YAML file with the object description for Ancient Terracottas, cat. 1. Notice how readable it is, with only a few bits of code, like the asterisks around klismos, which indicate italics.
I won’t say that using these new tools was painless—I definitely developed greater sympathy for the designers who enter the text corrections for our print books—but nor was it as painful as I worried it might be. I struggled with the bits of HTML included in the text. The elegantly small-capped BC, which appears hundreds of times throughout the manuscript—is surrounded by HTML markup, making the experience of reading the Markdown files much more challenging. But using Atom’s powerful find-and-replace function made, say, correcting a misspelled name that appears throughout the book much easier, and as I spent more time in GitHub, I got more comfortable using the tools that make it unique.
And of course, these tools serve a goal far bigger than “just” the one hundred thousand words and hundreds of images that comprise Ancient Terracottas from South Italy and Sicily. Only two months after its publication, we launched Roman Mosaics, and other books using the same platform are under way. The platform allows for the books to be experienced on our website, downloaded as PDFs, e-books, and datasets, or ordered as paperbacks.
To me, more remarkable than the form they take now is that they are built to last. While these publications take advantage of the latest technology, the fact that they are built from plain-text files and as open-source static sites helps to ensure they will never be dependent on soon-to-be-out-of-date platforms and are much more likely to be compatible with the technologies of the future. And because each catalogue is also available in its project repository on GitHub, anyone can see how the publications were made, from text corrections to code.
It’s fitting, then, that the first book built on the Getty’s new online publishing platform is about ancient terracottas, which were created from molds, circulated widely throughout the Mediterranean, and have survived for thousands of years. “Create once, publish everywhere” is something of a mantra in the digital publishing world…but as with many things, the ancients beat us to it.



Brava! It’s about time someone addressed the differences (and similarities) between editing for print and digital publishing. To make it so clear and remove much of the mystery-based fear is quite a feat. For years, now, publishers have tended to turn a little green around the gills when the idea of digital publishing of heavily illustrated books is raised. The litany of “but-you-cant’s…” is endless, so the clarity with which you present your experience and the basic approach is much appreciated. That said, I wonder if your kind of thinking and generosity in sharing it may be in part because Getty Publications is part of a nonprofit, scholarly organization. Frequently I get the chilling impression that many trade publishers almost “need” to cling to the you-can’ts in order to dissuade their art-book authors from asking to have their books provided as both print and digital publications and, perhaps, to ramp up the perceived cost of digital book production to use as a bargaining chip when discussing royalties and advances. Thank you so much for this excellent post.
Thanks so much for your comments, Brian! I’d be lying if I said we didn’t turn a little green here, too—the rights issues can be so complicated for digital art books and of course we’ve done some handwringing as we’ve tried to figure out how to make our digital books as beautiful as our print ones. But we are very lucky in that there’s quite a bit of support for digital publishing here, and I think you are right to connect that support to our mission as a cultural institution.
If I may ask, are you using a static site generator? LIke Jekyll or Hugo?
Yup, Middleman! More details on the project repository: https://github.com/gettypubs/terracottas
I was fascinated to come across this article. I teach a masters programme in Digital Publishing and this narrative offers a good insight into a possible way of working to deliver across multiple platforms.
It seems to me though, that there might be a better way to deal with the early text editing phase than using track changes with Word. Why not use an online collaborative editing system that processes content that is already in a git repository? The text will then already be in markdown.
If there was ever a chance for someone from Getty to give a guest lecture to my students at Oxford Brookes University, then please contact me.