
Meet Rob Sanderson, the Getty’s first-ever semantic architect. Rob came to the Getty in April from Stanford University Libraries, where he focused on facilitating technology collaboration, earning the nickname “the Bumblebee.” In addition to holding a PhD in French and history, he’s also a world-renowned information scientist with expertise in linked open data and the digitization of cultural heritage.
Rob is a passionate advocate for open culture, and is working to advance the Getty’s efforts to make our digital projects open, collaborative, and useful to the widest possible audience. He’s co-chair of the Web Annotation Working Group at the W3C, the international standards body for the Web, and a key player in the International Image Interoperability Framework (IIIF) movement—more on both of these below.
Originally from Christchurch, New Zealand, Rob arrived in L.A. via Los Alamos (five years as a scientist at the National Laboratory and a connoisseur of New-Mexican green chile) and Liverpool (where he earned his PhD and taught computer science). Depending on how you count it, Rob either has the longest commute to the Getty or the shortest: he flies in from his home in the Bay Area each week and stays at a local Airbnb just steps away from the Getty Center.
I spoke to Rob about his new role and how he’s working to increase collaboration in the cultural heritage community.
Annelisa Stephan: Let’s start with your title, “Semantic Architect.” What is that?
Rob Sanderson: It has two parts. Semantics is around the meaning of things—making sure that when we’re talking about something in an information system that a machine uses, we all mean the same thing. “Painting,” for example: are we talking about the activity of painting, or are we talking about the physical object?
“Architect” is also important. I do designs for information systems that represent the requirements of the project and are nice to work with, both for end users and for software developers, in the same way as architects of physical structures need to understand physical requirements and how people will use it
Openness of information is something that’s important to you. Why?
Yes—in fact, the Open Content policy of the Getty was one of the aspects that drew me strongly here. That policy is really valuable for the community at large.
There’s a motto in web architectural development that the most interesting thing that anyone will do with your data will be done by someone else. So, if you provide it in a useful way, people will find all sorts of interesting things to do with it.
You’re heavily involved with IIIF, which focuses on making images more shareable and usable. What is IIIF, exactly?
IIIF [pronounced “triple eye eff”], the International Image Interoperability Framework, is a community of museums, national libraries, research institutions, and companies that develops standards around images and access to images. It also builds software that implements those standards, and uses the software to provide access to content.
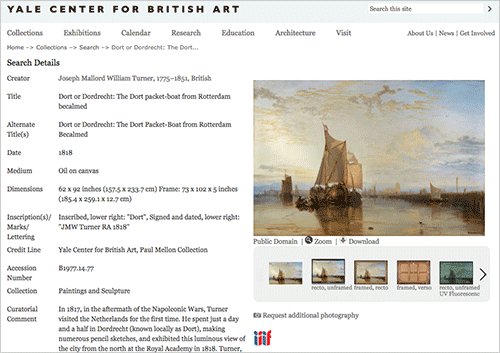
A sample IIIF implementation of digital collections content from the Yale Center for British Art
IIIF partners, including the Getty, are focused on providing access to their images so people can use them from wherever a IIIF image viewer happens to be deployed. It will be useful to scholars to compare and contrast images, but also to the wider public, because we’ll all be able to experience things we could never do in real life—like putting two paintings by the same artist next to each other on the screen, paintings that would never sit next to each other on a gallery wall because they’re owned by organizations in different countries, for example.
Looking ahead five years, what are your hopes for IIIF?
We’ll see a lot of interesting applications—in cultural heritage and research, but also with popular mashups along the sorts of lines that Flickr enables.
We’re also looking to integrate audiovisual materials with artworks. For example, let’s say you have a medieval manuscript with music in it. It would be great to hear the audio of someone performing that music, or a video of a lecture about the manuscript, and allow people to build interesting things on top of that content as well.
You could also transcribe the lyrics, so you’d have an alignment of lyrics and the text that could be read via screen reader. Someone who is deaf could feel the music at the same time as seeing the image—or a bouncing ball could appear on screen to indicate the tempo.
So IIIF has accessibility implications.
Absolutely. We try to be as accessible as possible. So, while the word “image” is in the title of IIIF, we hope to be still interesting and important to people who have limited sight.
Tell us about web annotations, which you’re working on with the W3C.
Annotations take social media to the next level: anyone can make a comment about anything online, and have those annotations be distributed across different systems on the web.
What’s the benefit of inviting anyone to comment on anything?
It’s about inclusion and diversity.
If you were to comment and provide useful information about a news story—let’s say, “I was there and here are my photographs”—you would enrich the conversation online. If you were editing a news story that was on both the Washington Post and the L.A. Times, the annotation wouldn’t have to be copied between those two different platforms if they were both using it. We need to be aware, though, of the potential for abuse and limit the damage of any negative interactions that technology makes possible on a global scale.
How do you envision annotation playing out in the cultural heritage community?
It could spur discussion around the objects we look after. Maybe we’d find information that we’d have never known because the scholar was working by themselves—or because they’re not a scholar, but happen to know someone or something. If we can provide a friendly and welcoming environment for all those conversations to happen, then scholars and the public would be able to interact in interesting and noble ways.
Tell us what you’re working on now.
The two projects I’m most involved in here right now beyond IIIF are Linked Open Data for the Getty Vocabularies, and the redesign of the Getty Provenance Index.
The Getty has a fabulous index of provenance information—and of course, we’re not working alone in this field. By working in the wider community, we can make sure that our work and the work of other institutions—such as Carnegie Museums’ Art Tracks project—will dovetail together. The two systems will be able to work together, so we can fill in some of their missing information, and they can fill in some of our missing information. Smaller institutions will be able to contribute their knowledge to create a much greater theater of information than any single institution could provide by themselves.
What aspect of the Getty Vocabularies are you working on currently?

The Getty Vocabularies provide Linked Open Data downloads and support at vocab.getty.edu
The Vocabularies are a foundational piece of infrastructure for the cultural heritage community. There’s been a lot of use of the vocabularies as Linked Open Data—but the data is not yet easy to use. One of the things we’re doing is talking with Google, who have an ontology called schema.org that’s designed to make it easy to find things on the web—people, places, creative works. If we can provide the Getty Vocabulary data in a simpler format as well as the rich descriptions we have now, we hope we’ll see a real explosion in use of them.
You’re interested in creating collaboration in the wider digital cultural heritage community, but also in creating collaboration within the Getty. What does that look like?
Here’s an example. We have a lot of images being produced across the institution—the Getty Museum has artwork images, for example, and the Research Institute has hundreds of thousands of digitized book pages. Getty Publications, meanwhile, needs to have reliable access to image content that they can put into online publications. If we can provide central infrastructure that meets everyone’s requirements, it will be easier to manage the information, and everyone would benefit from that.
What form would this central infrastructure for images take? For example, we have a system where we house artwork information (TMS), and an image repository where we store digital media. Where does your work come in?
My work sits in between these layers. It’s the information systems equivalent of the conversations people have. The vocabularies can say, “Hey, TMS, we’ve got this update,” and TMS says, “Oh, okay, cool. I can make use of these things.” So, it’s about facilitating interactions.
For internal communications, my role is also helping software engineers across the Getty work together to think about our requirements for systems.
It sounds like you spend a lot of time working with people, not just technology.
Yeah, it’s about 80% facilitation, conversations, and politics, and 20% technical work.
Looking at the cultural heritage field broadly, are there any projects that you see as great examples of collaboration, technology, or both?
The trend towards national or international aggregations, like Europeana and DPLA, the Digital Public Library of America. They’ve been able to galvanize their constituents into providing information that’s accessible to people but also to machines, and in a consistent way. This is so encouraging. And they’ve both been able to invest in community at the same time as technology—perhaps to the same degree as I said about my own work: 80% community, 20% technology. Without the community, technology doesn’t do much good at all.
What motivates you?
I’m motivated by helping cultural institutions come together. We need to work together to ensure that our content is shared and shareable, and that our infrastructure for images and metadata can be reused and co-developed to serve multiple institutions’ purposes. If we don’t work together, we’ll all be developing many mediocre things that no one really cares about. In five years’ time we’d be like, “Well, that wasn’t very good,” so we’d try something else, and just have another mediocre thing.
And if we work together and put in a bit of time up front to think about how it will look five years down the line? Yes, it’ll probably take longer than if we were to just throw money at the problem and do it alone, but we’ll end up in a much better place for the community.



Comments on this post are now closed.